Minority Collective Action for User-Side Fairness
Can people collaborate to make ML fair?
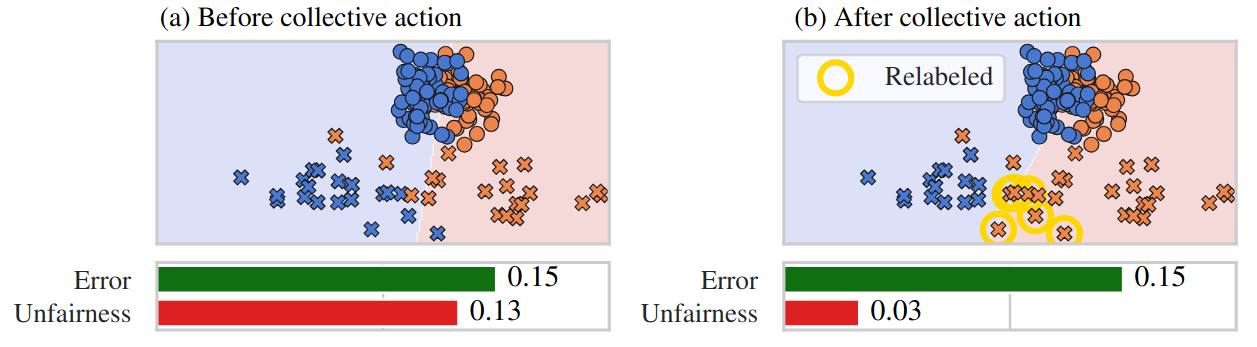
Minority-only collective action can substantially improve fairness. With only 6 label flips, the fairness violation of logistic regression goes down by over 75% with only a negligible increase in prediction error. Circles and crosses represent majority and minority points, respectively.
Resources
- For more details, results and limitations, please read our research preprint.
- A conference poster presenting the paper.
- A recording of a talk summarizing the work.
- A recording of a popular-science talk and the slides from the Tübingen Days of Digital Freedom.
Introduction
A standard task in machine learning is classification, where the goal is to train a classifier $h$ to return the correct label $y$ for given features $x$. In many cases, measuring the classifier’s accuracy on a test set is enough to assess its quality. In high-stakes settings, we need to be more careful because the classifier may affect people’s lives: it may predict whether a person will default on a bank loan, determine whether a candidate is a good fit for a job, or recommend a medical treatment. For example, we might examine accuracy across demographic groups and find that accuracy for the minority is much lower than accuracy for the majority, as illustrated below.
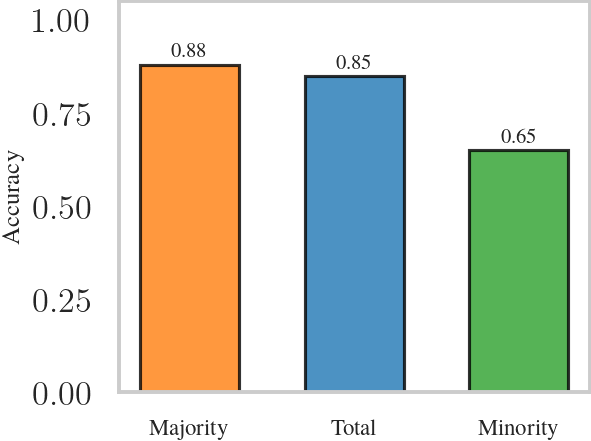
This is one form of unfairness in machine learning, where a classifier treats demographic groups differently. Reducing unfairness in machine learning is an active line of research, and many solutions attempt to address it by modifying the training pipeline. These approaches can improve fairness to varying degrees, but they often come with costs in overall accuracy, added pipeline complexity, or organizational buy-in.
For a company focused on maximizing profit, a loss in accuracy can translate into lower profit. As a result, the company may avoid implementing fair learning. Still, this does not mean we should lose hope for fairness. Many companies now train models on data they obtain from end users, and those users have agency over what they report. This raises the central question: Can users modify their data in a way that makes the company’s classifier fairer? The core idea is that a coordinated minority group can strategically relabel its own data to improve fairness, without changing the firm’s training pipeline. Questions like this fall under the field of algorithmic collective action (ACA).
Algorithmic collective action in machine learning
The basic setting for ACA is a firm training a classifier on user data [1]. We can think of each user as contributing a sample $\left(x,a,y\right)$, where $x$ is the feature vector, $a$ is a sensitive attribute denoting group membership ($a=0$ for the majority and $a=1$ for the minority), and $y$ is the label. In this setting, users do not have access to the training pipeline, but they can change the data they report. Of course, if a single person changes their data, the update will have a negligible effect on the classifier. However, if many people coordinate their changes as a collective, they may have enough statistical weight to steer the model toward the collective’s goal. Formally, if the collective comprises a fraction $\alpha$ of the population, then the data distribution is $P_{\alpha}$: \(P_{\alpha}=\alpha P^{*}+\left(1-\alpha\right)P_{0},\) where $P_{0}$ is the base population distribution and $P^{*}$ is the collective distribution.
As a more concrete case, assume that the collective wants the firm’s classifier $h$ to be invariant to a transformation $g$. In other words, for any features $x$, the goal is to have $h\left(x\right)=h\left(g\left(x\right)\right)$; the classifier returns the same output whether $x$ was transformed by $g$ or not. If $g$ changes group-identifying information encoded in the features, then making $h$ invariant to $g$ erases that signal from the classifier’s predictions. Consequently, we measure the success of the collective as \(S\left(\alpha\right)=P_{0}\left[h\left(g\left(x\right)\right)=h\left(x\right)\right],\) the probability, under the base distribution, that the classifier gives the same prediction. In this ideal erasure strategy, the collective distribution $P^{*}$ is defined by changing the reported labels $y$ according to the rule \(y\rightarrow\arg\max_{y^{\prime}\in\left\{ 0,1\right\} }P_{0}\left(y^{\prime}|g\left(x\right)\right).\) In words, each collective member would change their label to the most probable label with the transformed features. We then adapt this ideal strategy to the practical setting where counterfactual labels are unavailable and only minority members participate.
Linking between ACA and fairness
So far, we discussed two different subjects in ML: fairness and ACA. We can connect them by noting that if $g$ changes group membership information, then the success of a collective $S\left(\alpha\right)$, as defined above, measures how much the classifier $h$ ignores that information. This is a property we would expect from a fair classifier.
One way to encode group membership in $g$ is to use causality. Specifically, we assume the following simple causal model.
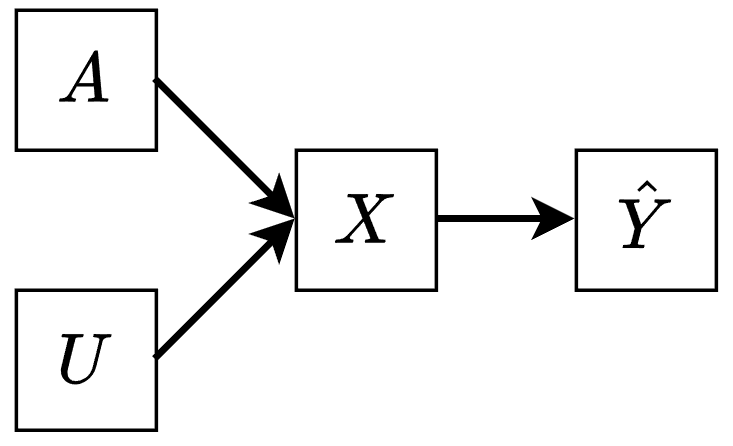
With this assumption, we can define the transformation $g$ as the counterfactual features that would be observed if group membership (A) were changed to the majority, which we denote as $g\left(x\right)=x_{A\leftarrow\text{Majority}}$. Using this counterfactual creates a close relation between the collective success $S$ and a minority-focused form of counterfactual fairness [2]. In particular, for a Bayes classifier, perfect collective success ($S=1$) is equivalent to minority-focused counterfactual fairness.
Designing a strategy for the minority
Even after defining $g$, a collective still cannot directly implement the label-changing strategy above because it requires access to counterfactual labels, which are generally intractable. We also restrict ACA participation to minority members, since majority members may prefer to maintain the status quo. This restriction means that not all collective members should change their labels; instead, the collective should select the most promising candidates. To solve both problems, we propose the following steps:
- Form a candidate pool from all minority collective members with a “negative” label.
- Estimate the likelihood of each candidate to have a counterfactual positive label.
- Flip the labels of the candidates with the highest likelihoods.
In our preprint, we expand on three methods for estimating these likelihoods. We call these methods Rank by probability (RB-prob), Rank by label (RB-label), and Rank by distance (RB-dist). RB-prob trains a model on majority data and scores candidates by their predicted probability of a positive label. RB-label counts how many of a candidate’s nearest majority neighbors have a positive label. RB-dist prioritizes candidates who are closest to majority examples with positive labels.
Evaluation of fairness
Since we lack access to the counterfactuals themselves, we also cannot directly evaluate counterfactual fairness. As a surrogate, we compute standard group-fairness metrics: statistical parity and equalized odds (EqOd). Statistical parity compares the rate of positive predictions between groups, while EqOd measures the average gap in false-positive and true-positive rates. For both metrics, lower values indicate less measured unfairness.
We first examine how the collective size $\alpha$, measured as a fraction of the minority, affects the achievable fairness.
For each $\alpha$, we record the fairness violation for different numbers of label flips, and plot the lowest violation per $\alpha$.
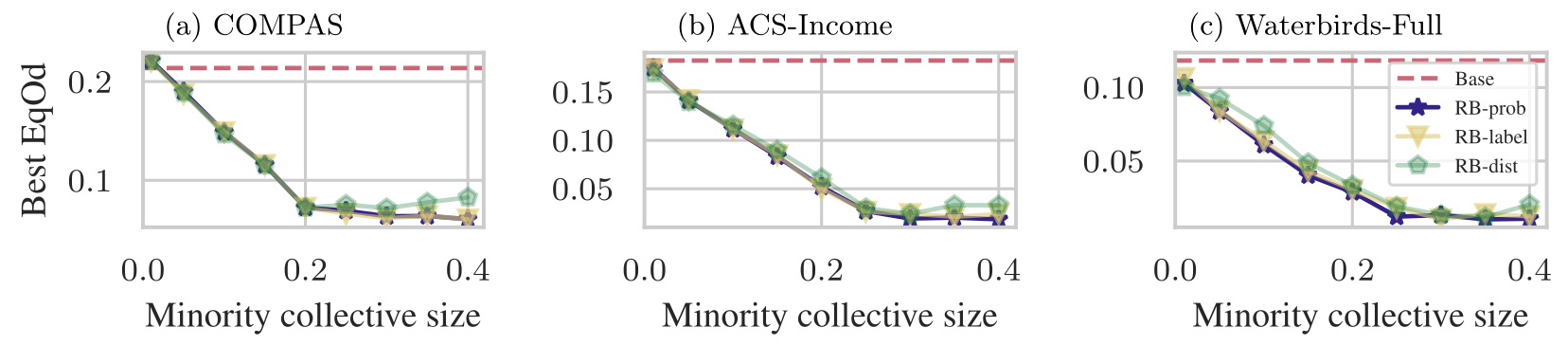 As the results above show, the best achievable EqOd improves as the collective size grows, until it saturates around $\alpha=0.3$.
This saturation reflects the limited power of a minority-only collective.
As the results above show, the best achievable EqOd improves as the collective size grows, until it saturates around $\alpha=0.3$.
This saturation reflects the limited power of a minority-only collective.
A deeper dive
The figure above shows similar behavior for all the three methods, but this fake trend exists because we plot the best results over changing the amount of label flips.
To take a closer look into the behavior of the methods, we fix the collective size $\alpha=0.3$ and observe how the fairness changes with increasing the number of flips.
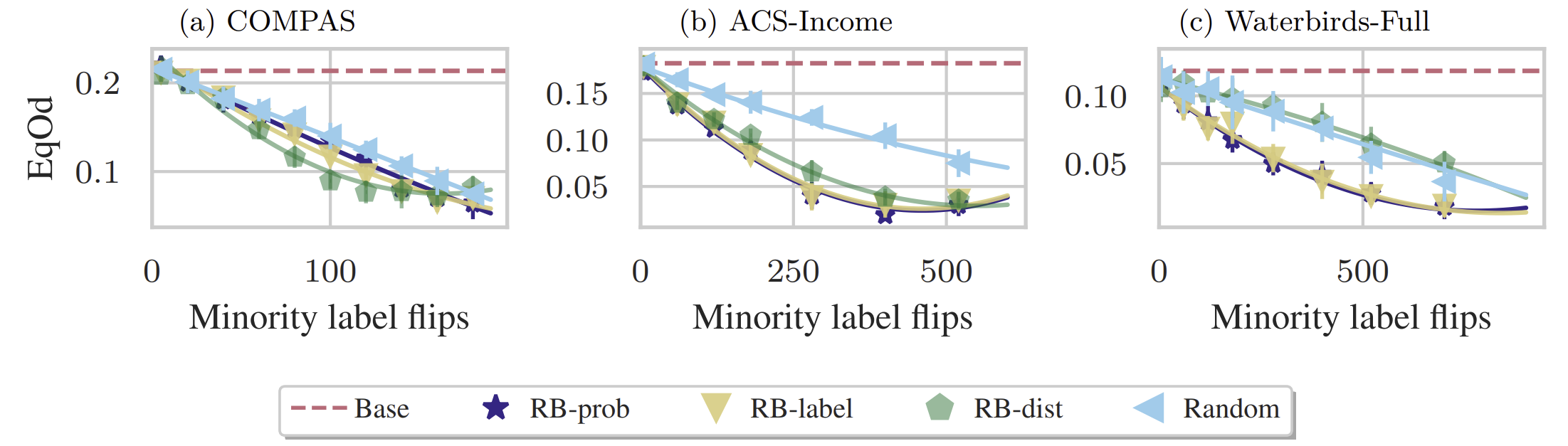 This result shows that the choice of counterfactual estimation matters.
While RB-dist performs slightly better on COMPAS, it performs worse on the other datasets.
The “Random” baseline flips random labels from the candidate pool, and always performs worse.
In case there is a limited budget for label flips, this result confirms that the collective should strategically decide which labels to flip.
This result shows that the choice of counterfactual estimation matters.
While RB-dist performs slightly better on COMPAS, it performs worse on the other datasets.
The “Random” baseline flips random labels from the candidate pool, and always performs worse.
In case there is a limited budget for label flips, this result confirms that the collective should strategically decide which labels to flip.
Comparing with firm-side methods
We also compare the collective approach with firm-side fairness methods, as shown below.
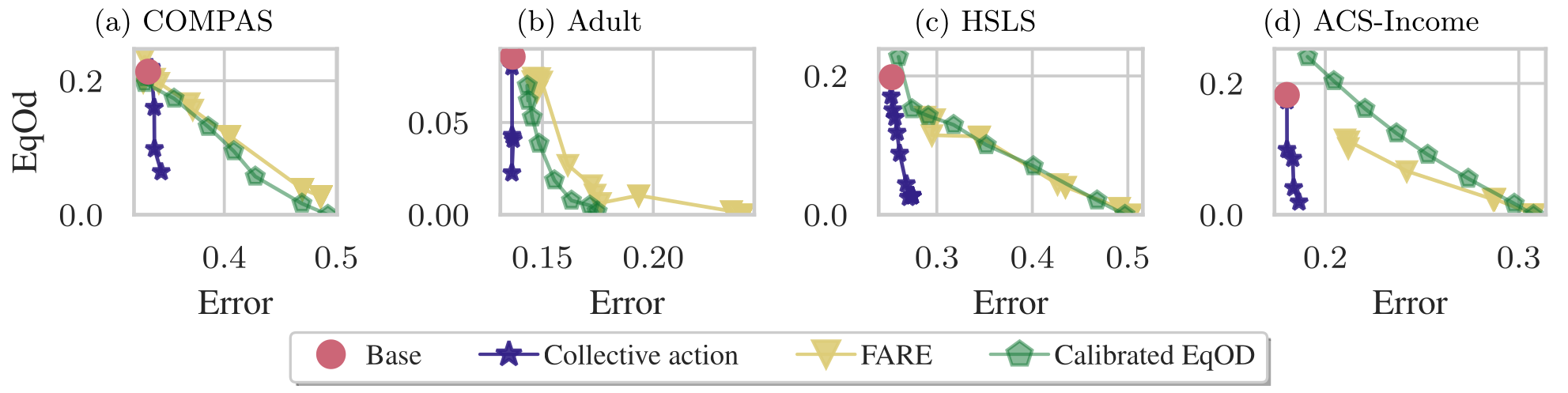 In this figure, we show the Pareto fronts of the different approaches by plotting the tradeoff between fairness violation (EqOd) and classifier error.
The comparison highlights two points:
In this figure, we show the Pareto fronts of the different approaches by plotting the tradeoff between fairness violation (EqOd) and classifier error.
The comparison highlights two points:
- In the low-error region, the collective approach can improve fairness with a smaller increase in prediction error.
- Firm-side methods can drive fairness violations closer to zero, but often only at a much higher cost in prediction error.
Taken together, minority ACA should not be viewed as a replacement for firm-side fairness methods, but as evidence that users may still have leverage when firms lack incentives to change their training pipelines. The striking result is that a coordinated minority group can often improve fairness with only a few label flips and without a substantial reduction in utility.
Conclusion
In this work we show that a minority collective can vastly improve fairness, with only a small cost in predictive error. We bridged between fairness and ACA to provide a model-agnostic practical algorithm to determine how best to implement the theoretical strategy. We hope this will shift focus to other method to fight unfairness in machine learning. For a more in-depth analysis, you can read the preprint here, or watch the recorded talk for a brief summary.
Collaborators
- Samira Samadi
- Amartya Sanyal
- Alexandru Țifrea
References
[1] Hardt, M., Mazumdar, E., Mendler-Dünner, C., & Zrnic, T. (2023, July). Algorithmic collective action in machine learning. In International Conference on Machine Learning (pp. 12570-12586). PMLR.
[2] Kusner, M. J., Loftus, J., Russell, C., & Silva, R. (2017). Counterfactual fairness. Advances in neural information processing systems, 30.